I was recently asked a seemingly innocent question: what's the optimal way to do a best-match retrieval?
Reasonable enough, until I was asked if there was a way to do it with…
it's gen ai bro, you wouldn't get it

Oh boy.
Lets take a step back.
The task
Users needed a way to search an internal structured knowledge database through a chatbot accessible via Slack or text messages. The knowledge base was organized using information tags, which could be either common words or place names.
Since the users always knew exactly what they were looking for, the bot's job was straightforward:
- Take the user's input text
- Match it to the tags in the database
- Return the best match
This simplified approach meant the bot didn't need to understand complex queries or context. It just needed to excel at matching input to existing tags and retrieving the associated information quickly and accurately.
The problem
Interface constraints presented a unique challenge. Since users would access the bot via Slack or text messages, we couldn't implement auto-complete or assume that input was being ran through built-in spell-checkers. This meant we needed to use best-effort matching in our search algorithm to handle potential misspellings and typos.
The solution
Add fuzzy search. Make a ticket? 3 story points. Done.
.
.
.
"But what if we really really need AI? Please Vlad. Just a little AI. A smidge of AI for our AI-enabled company. For our dear little chatbot? Okay?"
The solution (again)
OK. Let's try to add AI cheaply, without compromising the end result. What are our options?
- Direct file Q&A: The databases were pretty big. Napkin math told me they'd fit into contexts of some SoTA LLMs for direct QA, but in testing I got slow responses and decent but not satisfactory reliability. These problems are solvable, but given time and budget constraints I wasn't comfortable going further down this path.
- Combining Fuzzy Search with LLMs: Another idea was to use fuzzy search to find potential matches and then have an LLM refine the results. However, our database entries were already concise and specific. Introducing an LLM would increase latency without adding value.
- Semantic Search Using Embeddings: This led me to consider semantic search using embeddings. If the user's input couldn't be directly matched, we could generate an embedding of the input and compare it with embeddings of our indexed tags to find the closest match. This isn't what most people would consider AI, but we can implement it using the OpenAI API, which is close enough.
Some brief testing confirmed that option 3 was a viable solution. Significant typos would confuse it, but for the most part it was accurate. However, before settling on this option I decided to do some more methodical testing.
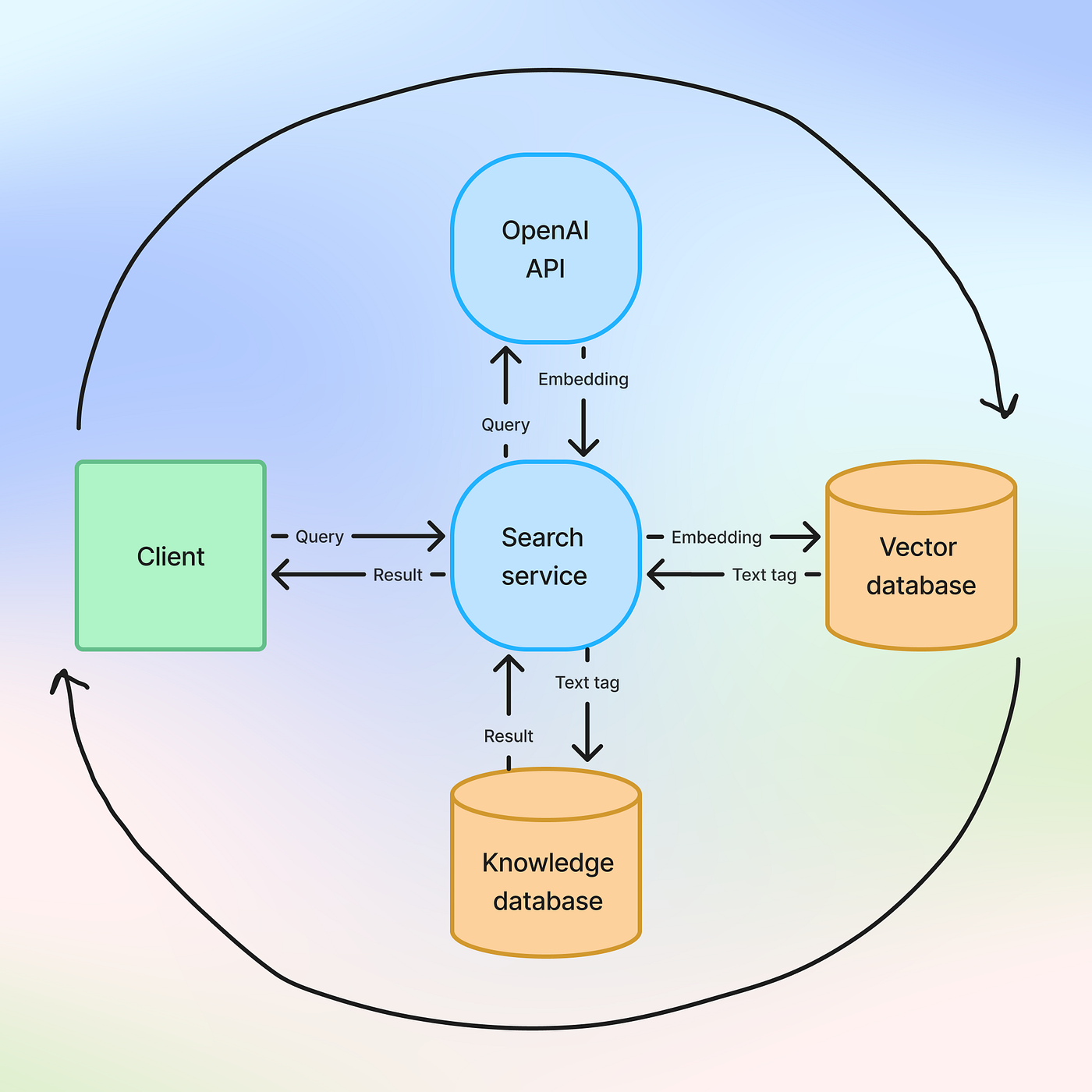
Fuzzy search vs n-grams vs word embeddings vs sentence encoders
To determine the most effective approach, I designed an experiment comparing:
- Fuzzy Search Algorithms
- N-Gram Models
- Word Embeddings
- Sentence Encoders
I created two datasets for my tests:
- A series of slightly misspelled words (1–3 characters off) and their correct spellings
- A series of similarly misspelled cities and their correct spellings
I chose these categories knowing that general words and place names are treated differently by embedding models due to their relative frequencies and usage patterns.
Benchmarking fuzzy search
First, I established our baseline using some common fuzzy search algorithms.
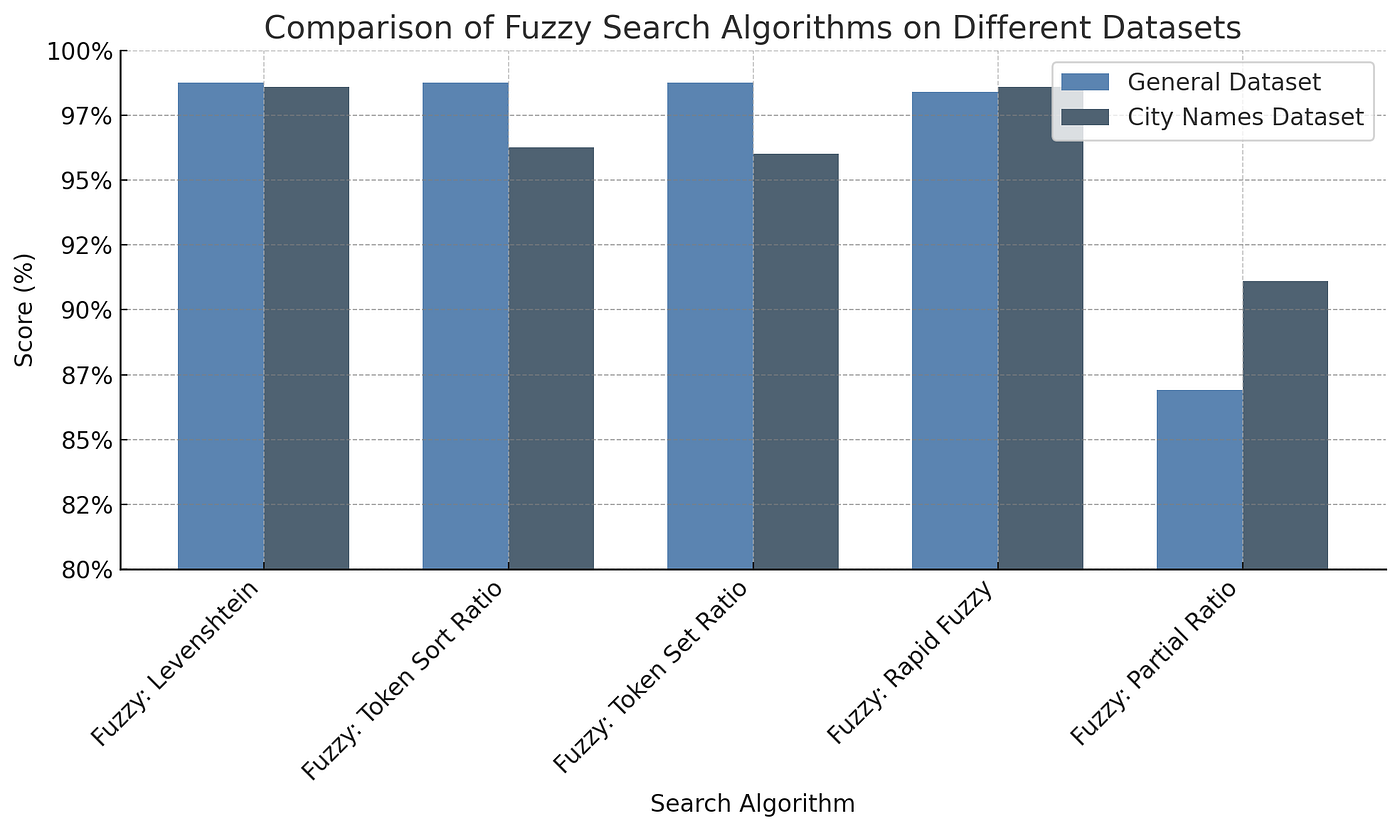
The benchmarks show that fuzzy search algorithms perform very well out-of-the-box for spelling correction on both the general dataset and city names dataset, with accuracies ranging from 86.9% to 98.7%. The Levenshtein distance and Token Sort/Set ratio methods achieve the highest accuracies. Remember, all the inputs in these datasets were misspelled, so this accuracy is pretty good.
N-grams
Next, I tested a few n-gram configurations.
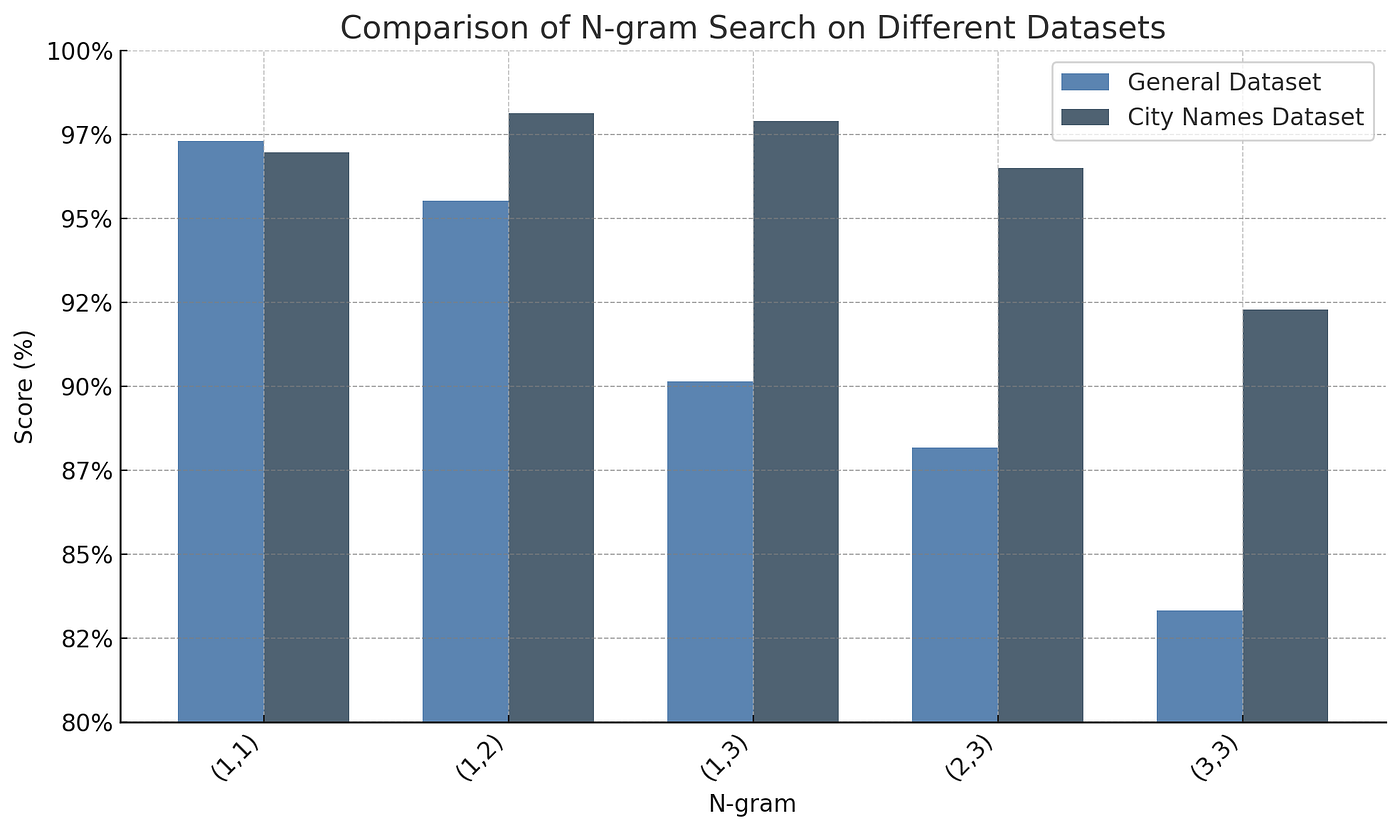
N-gram based approaches also perform quite well, especially on the city names dataset. Accuracies range from 83.3% to 97.3% on the general dataset and 92.3% to 98.1% on the city names. Performance tends to degrade as the n-gram size increases, likely because larger n-grams are more sensitive to spelling errors.
It's important to note that our strong n-gram results, particularly for (1,1) n-grams, are influenced by the relatively small size of our datasets. In larger datasets with more unique words, the performance of (1,1) n-grams will degrade due to their inability to distinguish anagrams and similar character rearrangements.
Higher-order n-grams may provide additional discriminative power, but will still struggle with long-range dependencies in character sequences. This idea is supported by the relative performance of (1,2) anagrams in the city dataset.
"AI" (embedding models)
Finally, I tested a large variety of embedding models. These ranged from traditional static word embeddings like GloVe to cutting-edge sentence transformers, including OpenAI's text-embedding-3 models.
With the exception of the text-embedding-3-large and text-embedding-3-small variants, all models tested were open-source and accessed through the sentence-transformers Python library.
Normal word dataset:
Model | Best Method | Best Accuracy | Cosine | Euclidean | Dot Product | Manhattan
---------------------------------------- | ---------------------- | ------------- | -------- | --------- | ----------- | ---------
text-embedding-3-large | 4-way tie! | 0.998208 | 0.998208 | 0.998208 | 0.998208 | 0.998208
text-embedding-3-small | 4-way tie! | 0.948029 | 0.948029 | 0.948029 | 0.948029 | 0.948029
LaBSE | Manhattan Similarity | 0.759857 | 0.749104 | 0.749104 | 0.749104 | 0.759857
all-roberta-large-v1 | Cosine Similarity | 0.729391 | 0.729391 | 0.729391 | 0.729391 | 0.725806
all-distilroberta-v1 | Cosine Similarity | 0.650538 | 0.650538 | 0.650538 | 0.650538 | 0.641577
all-mpnet-base-v2 | Cosine Similarity | 0.623656 | 0.623656 | 0.623656 | 0.623656 | 0.600358
stsb-roberta-large | Cosine Similarity | 0.612903 | 0.612903 | 0.602151 | 0.596774 | 0.612903
roberta-large-nli-stsb-mean-tokens | Cosine Similarity | 0.612903 | 0.612903 | 0.602151 | 0.596774 | 0.612903
paraphrase-xlm-r-multilingual-v1 | Cosine Similarity | 0.582437 | 0.582437 | 0.471326 | 0.525090 | 0.458781
msmarco-distilroberta-base-v2 | Dot Product Similarity | 0.577061 | 0.566308 | 0.537634 | 0.577061 | 0.526882
multi-qa-mpnet-base-dot-v1 | Dot Product Similarity | 0.562724 | 0.555556 | 0.551971 | 0.562724 | 0.548387
paraphrase-multilingual-mpnet-base-v2 | Dot Product Similarity | 0.537634 | 0.523297 | 0.446237 | 0.537634 | 0.439068
xlm-r-large-en-ko-nli-ststb | Cosine Similarity | 0.530466 | 0.530466 | 0.494624 | 0.498208 | 0.500000
stsb-roberta-base | Cosine Similarity | 0.523297 | 0.523297 | 0.489247 | 0.512545 | 0.476703
all-MiniLM-L6-v2 | Manhattan Similarity | 0.492832 | 0.491039 | 0.491039 | 0.491039 | 0.492832
distiluse-base-multilingual-cased-v2 | Cosine Similarity | 0.473118 | 0.473118 | 0.417563 | 0.442652 | 0.422939
paraphrase-multilingual-MiniLM-L12-v2 | Dot Product Similarity | 0.412186 | 0.405018 | 0.315412 | 0.412186 | 0.313620
paraphrase-MiniLM-L3-v2 | Cosine Similarity | 0.367384 | 0.367384 | 0.290323 | 0.347670 | 0.290323
nli-roberta-base | Manhattan Similarity | 0.333333 | 0.327957 | 0.327957 | 0.313620 | 0.333333
nq-distilbert-base-v1 | Euclidean Similarity | 0.288530 | 0.286738 | 0.288530 | 0.283154 | 0.286738
average_word_embeddings_glove.6B.300d | Dot Product Similarity | 0.277778 | 0.261649 | 0.114695 | 0.277778 | 0.125448
distilbert-base-nli-stsb-mean-tokens | Cosine Similarity | 0.263441 | 0.263441 | 0.256272 | 0.250896 | 0.261649
bert-base-nli-mean-tokens | Manhattan Similarity | 0.225806 | 0.216846 | 0.218638 | 0.211470 | 0.225806Places dataset:
Model | Best Method | Best Accuracy | Cosine | Euclidean | Dot Product | Manhattan
---------------------------------------- | -------------------- | ------------- | -------- | --------- | ----------- | ---------
text-embedding-3-large | Manhattan Similarity | 0.955607 | 0.953271 | 0.953271 | 0.953271 | 0.955607
LaBSE | Cosine Similarity | 0.911215 | 0.911215 | 0.911215 | 0.911215 | 0.904206
text-embedding-3-small | 3-way tie! | 0.894860 | 0.894860 | 0.894860 | 0.894860 | 0.890187
all-distilroberta-v1 | Cosine Similarity | 0.768692 | 0.768692 | 0.768692 | 0.768692 | 0.738318
stsb-roberta-large | Euclidean Similarity | 0.738318 | 0.735981 | 0.738318 | 0.719626 | 0.733645
roberta-large-nli-stsb-mean-tokens | Euclidean Similarity | 0.738318 | 0.735981 | 0.738318 | 0.719626 | 0.733645
msmarco-distilroberta-base-v2 | Cosine Similarity | 0.735981 | 0.735981 | 0.724299 | 0.728972 | 0.710280
stsb-roberta-base | Cosine Similarity | 0.728972 | 0.728972 | 0.693925 | 0.726636 | 0.689252
all-roberta-large-v1 | Cosine Similarity | 0.654206 | 0.654206 | 0.654206 | 0.654206 | 0.651869
paraphrase-xlm-r-multilingual-v1 | Cosine Similarity | 0.609813 | 0.609813 | 0.523364 | 0.525701 | 0.518692
distiluse-base-multilingual-cased-v2 | Cosine Similarity | 0.605140 | 0.605140 | 0.525701 | 0.462617 | 0.539720
paraphrase-multilingual-mpnet-base-v2 | Cosine Similarity | 0.565421 | 0.565421 | 0.492991 | 0.553738 | 0.485981
multi-qa-mpnet-base-dot-v1 | Euclidean Similarity | 0.553738 | 0.542056 | 0.553738 | 0.518692 | 0.539720
nli-roberta-base | Manhattan Similarity | 0.507009 | 0.504673 | 0.504673 | 0.469626 | 0.507009
all-mpnet-base-v2 | Cosine Similarity | 0.507009 | 0.507009 | 0.507009 | 0.507009 | 0.485981
paraphrase-multilingual-MiniLM-L12-v2 | Cosine Similarity | 0.497664 | 0.497664 | 0.441589 | 0.397196 | 0.446262
xlm-r-large-en-ko-nli-ststb | Cosine Similarity | 0.481308 | 0.481308 | 0.429907 | 0.464953 | 0.427570
all-MiniLM-L6-v2 | Cosine Similarity | 0.478972 | 0.478972 | 0.478972 | 0.478972 | 0.474299
paraphrase-MiniLM-L3-v2 | Cosine Similarity | 0.455607 | 0.455607 | 0.413551 | 0.453271 | 0.411215
nq-distilbert-base-v1 | Cosine Similarity | 0.420561 | 0.420561 | 0.420561 | 0.420561 | 0.415888
distilbert-base-nli-stsb-mean-tokens | Manhattan Similarity | 0.413551 | 0.406542 | 0.406542 | 0.406542 | 0.413551
bert-base-nli-mean-tokens | Dot-Prod Similarity | 0.345794 | 0.334112 | 0.334112 | 0.345794 | 0.329439
average_word_embeddings_glove.6B.300d | Cosine Similarity | 0.189252 | 0.189252 | 0.165888 | 0.179907 | 0.168224Results and analysis
The embedding model comparison yielded intriguing results. On the general misspelled words dataset, OpenAI's text-embedding-3 models excelled, with the large variant achieving an impressive 99.8% accuracy and the small version reaching 94.8%. Other sentence transformers like LaBSE (76.0%) and RoBERTa-based models (61–73%) significantly outperformed static word embeddings, with GloVe managing only 27.8% accuracy.
The misspelled city names dataset presented a greater challenge, but the performance hierarchy remained consistent. Text-embedding-3 maintained its lead (95.6% for large, 89.5% for small), closely followed by LaBSE at 91.1%. GloVe's performance dropped further to 18.9% on this dataset.
Error analysis revealed common challenges across models:
- Confusion between similar sounding city and state names (e.g. "Mariland" predicted as "Maricopa" instead of "Maryland")
- Challenges with technology-related terms like "smartfone" being predicted as "smartwatch" instead of "smartphone"
- Difficulty with multi-word terms that are run together, like "searchengine" for "search engine"
The Verdict
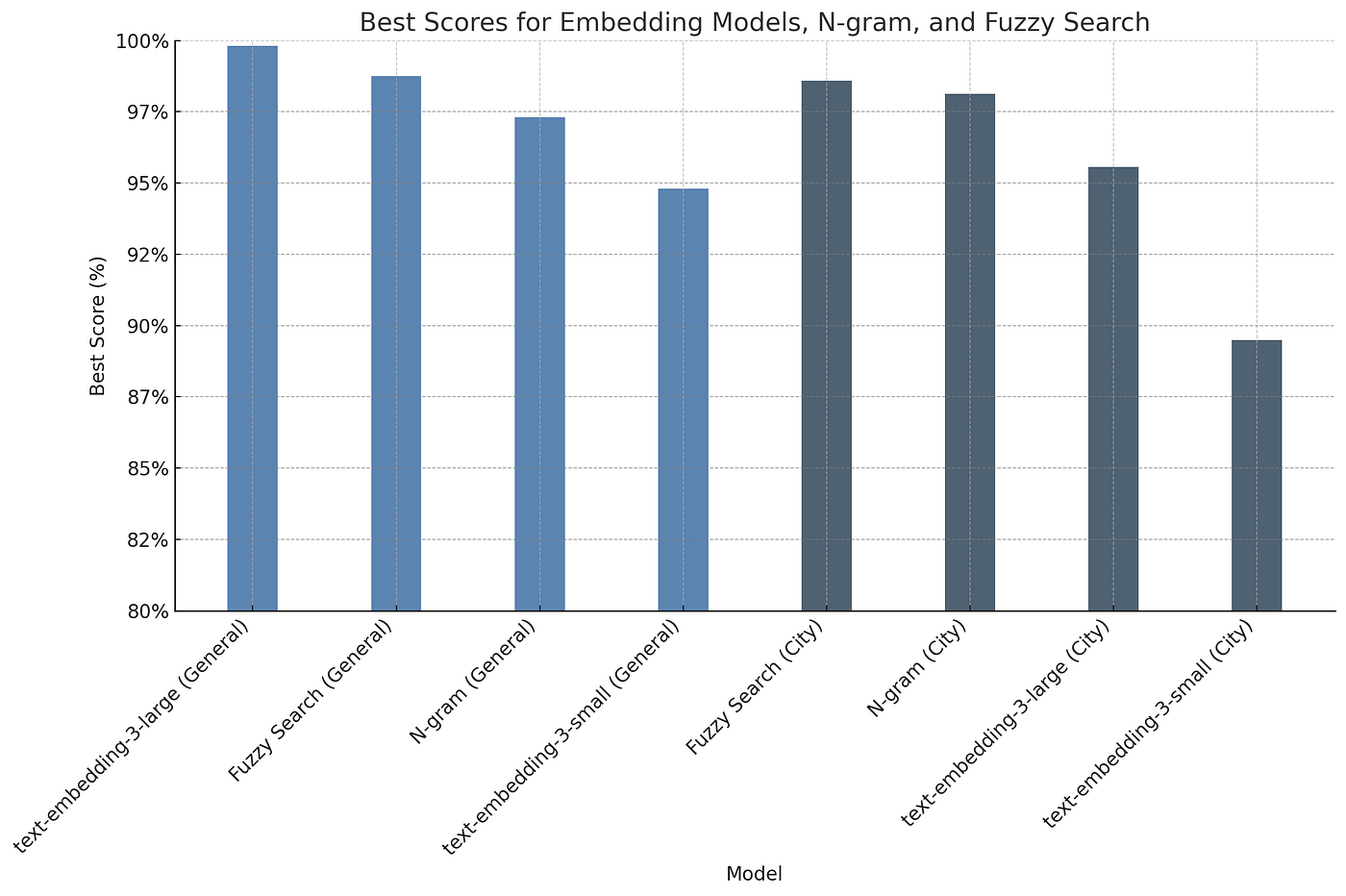
Embeddings put on a good show, but even the mighty text-embedding-3 couldn't quite match the 96–98% accuracies of fuzzy search on the city names dataset. Fuzzy search remains the most robust approach for domain-specific data.
Nevertheless, sentence transformer embeddings, particularly state-of-the-art models like text-embedding-3, have emerged as a strong alternative for general spelling correction tasks. Their performance is now sufficiently high to consider them for practical applications.
Based on these findings, I recommended the text-embedding-3-large model for error correction on non-domain specific tags. This choice satisfies the "AI" requirement while delivering performance that justifies its implementation.
An additional advantage is the ease of upgrading to future iterations of the model, allowing for seamless performance improvements with minimal effort. As these models continue to evolve, there may even be potential to expand their use to new domain-specific tasks.
Takeaways
In product development, it's crucial to recognize that the technically optimal solution isn't always the most appropriate choice in a business context.
Balancing stakeholder expectations, technical robustness, and available resources is a complex challenge. Often, implementing a "good enough" solution is the best approach, especially when considering time and budget constraints.
The key lies in making data-driven decisions, which provide empirical evidence to justify choices to stakeholders and ensure that selected solutions are grounded in facts rather than assumptions. This approach not only satisfies immediate business needs and resource limitations but also builds trust between technical teams and other stakeholders.